I use ride-hailing apps fairly often, so I was curious whether Uber or Lyft is cheaper on average. To find out, I downloaded my complete ride history from both companies and compared what I paid across 477 trips.
The short answer is that Lyft was cheaper most of the time. Across 340 Uber rides and 137 Lyft rides, Lyft had a lower aggregate cost per mile and per minute, and it was cheaper across every distance band.
This is not a comparison of simultaneous quotes for identical trips. The rides took place at different times and in different locations, so the results describe my own experience rather than guarantee which app will be cheaper for any particular trip.
The overall comparison
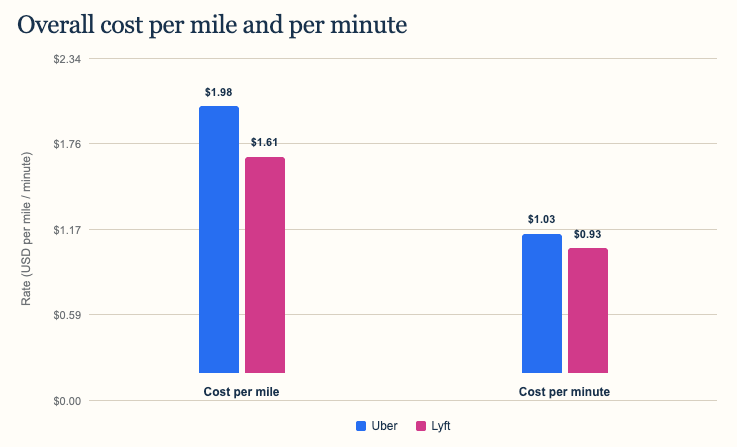
To compare rides of very different lengths, I divided total spending by total miles and total travel minutes for each service. On that basis, Uber averaged $1.98 per mile and $1.03 per minute, while Lyft averaged $1.61 per mile and $0.93 per minute. That made Lyft about 19% cheaper per mile and 10% cheaper per minute.
Aggregate rates are calculated as total cost divided by total miles or minutes, so each mile or minute carries equal weight.
Short rides are expensive per mile
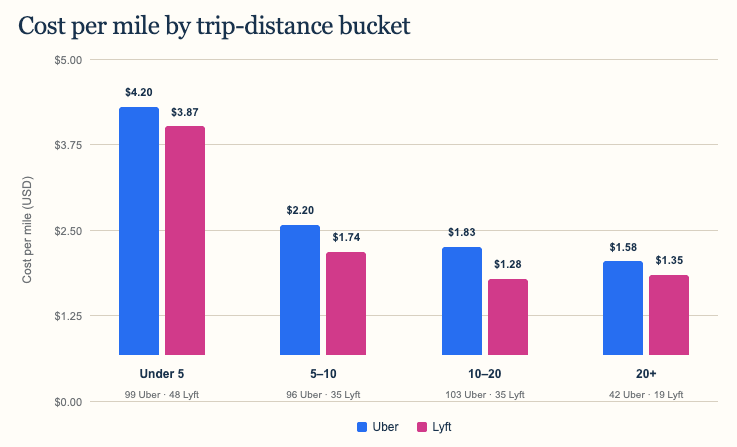
Rides under five miles cost roughly $4.20 per mile on Uber and $3.87 on Lyft. Once trips reached 20 miles, those figures fell to about $1.58 and $1.35, respectively. Base fares and fixed fees get spread across more miles on longer trips.
Lyft was cheaper per mile in all four distance groups. Its advantage was modest for rides under five miles and for rides over 20 miles, but wider in the middle: Lyft cost about 21% less per mile for five-to-ten-mile trips and about 30% less for ten-to-twenty-mile trips.
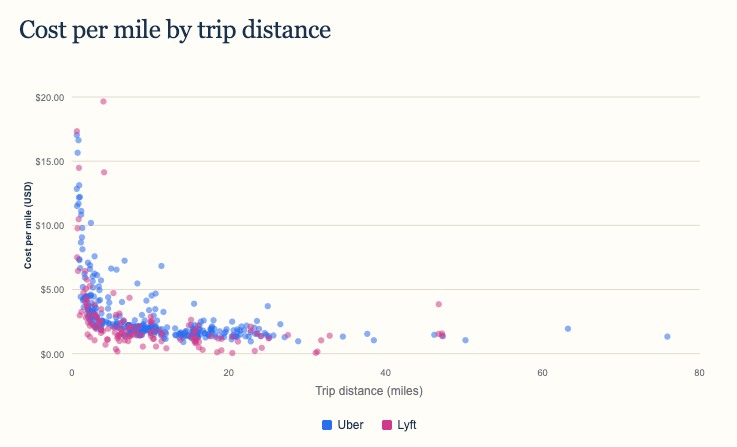
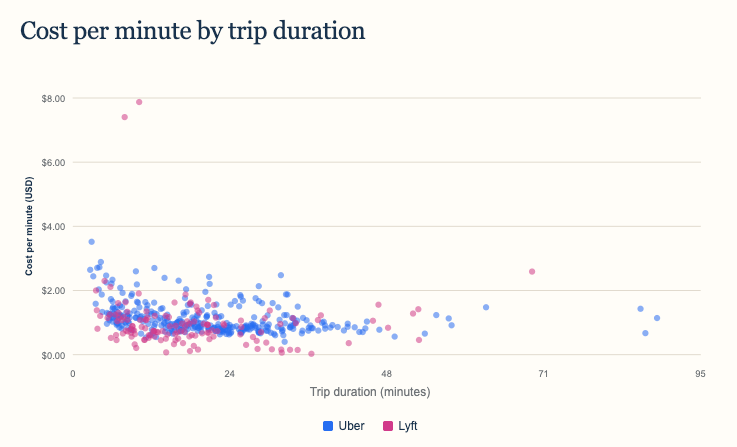
The individual rides show why an average only tells part of the story. Prices vary widely on short trips, while longer rides cluster into a narrower cost-per-mile range. Surge pricing, fees, location, and ride type can easily overwhelm the average on any single booking.
The comparison by trip duration
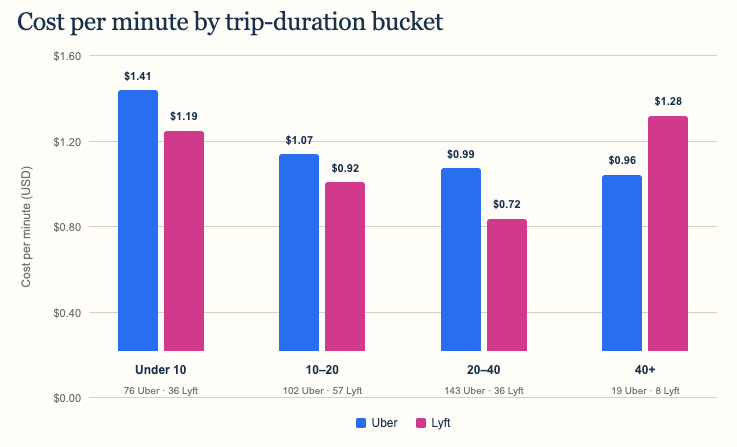
Cost per minute also generally declined as rides got longer. Lyft was cheaper in the first three duration groups: under 10 minutes, 10–20 minutes, and 20–40 minutes. The largest gap appeared in the 20–40 minute group, where Uber averaged $0.99 per minute versus $0.72 for Lyft.
Uber reversed the result for rides lasting 40 minutes or more, at $0.96 per minute compared with $1.28 for Lyft. That result needs extra caution, however: the group contains only 19 Uber rides and eight Lyft rides, so a handful of unusual fares can move the average substantially.
As with distance, the scatter plot makes the variation visible. Most rides follow a broad downward trend, but there are outliers in both services. Checking both apps before booking still matters more than the historical average.
Location changes the picture
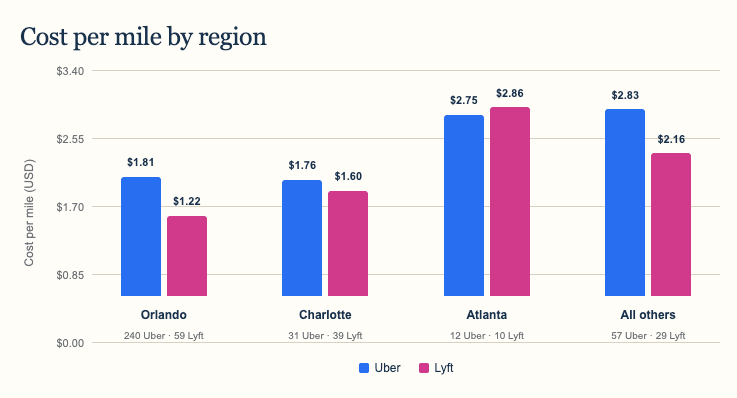
Most rides in the dataset came from Orlando, Charlotte, and Atlanta, so I separated those markets and combined the rest. Lyft was cheaper per mile in Orlando and Charlotte, as well as across the combined “other regions.” Atlanta was the exception: Uber averaged $2.75 per mile compared with Lyft at $2.86.
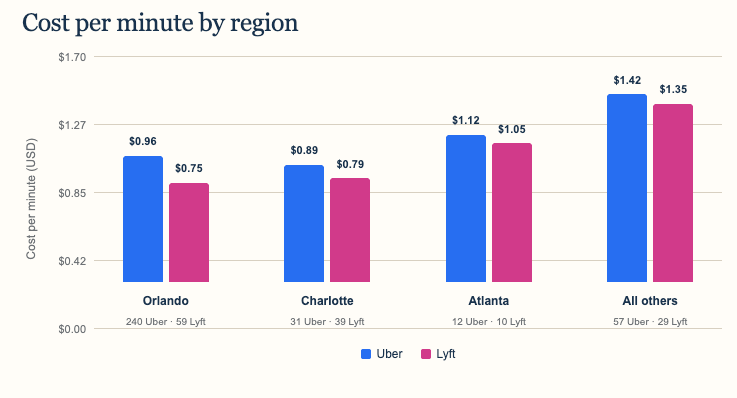
On a per-minute basis, Lyft was cheaper in all four regional groups. The difference was largest in Orlando, where Uber averaged $0.96 per minute and Lyft averaged $0.75. The two services were much closer in Atlanta and in the combined group of other regions.
So, which one is cheaper?
For my ride history, Lyft wins the overall comparison. It was cheaper per mile, cheaper per minute, and cheaper across every distance band. Uber still performed better in a few slices of the data, most notably rides over 40 minutes and cost per mile in Atlanta, but those groups were relatively small.
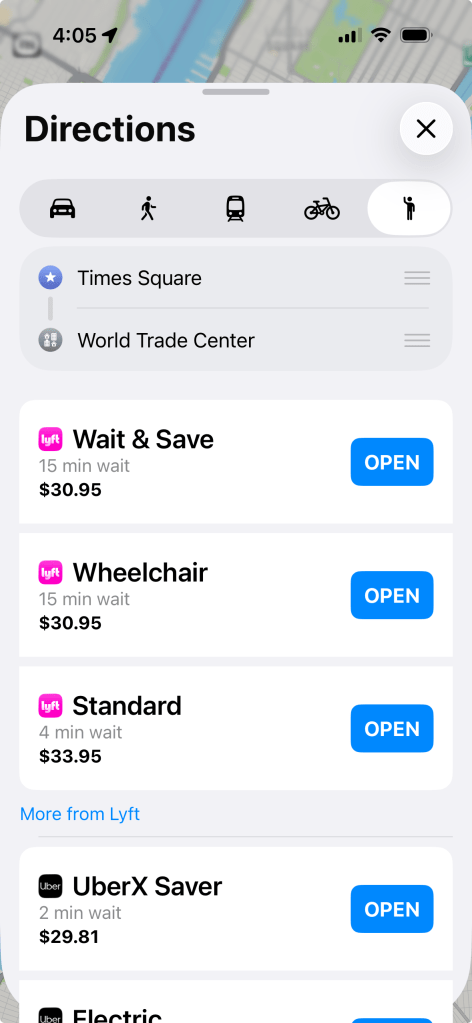
That said, when it comes time to book a ride I always check both services to see which one offers the cheapest fare for where I’m going. If you have an iPhone this can be done relatively easily using the Apple Maps app. For example, in the below screenshot it is actually Uber that is cheaper this time around.
In the United States, homeownership is rarely presented as one housing option among several. It is treated as a milestone, a financial necessity, and evidence that someone has successfully entered adulthood.
Politicians promise to increase the homeownership rate. Financial advice often treats renting as a temporary condition to escape. Rent payments are described as “throwing money away,” while mortgage payments are described as “building wealth.” Even people who are perfectly satisfied renting are regularly asked when they plan to buy.
Behind all of this is an assumption that is rarely questioned: more homeownership is always better.
But homeownership is not inherently better than renting. Both have advantages and disadvantages. More importantly, policies designed to maximize homeownership can harm renters, future homebuyers, and ultimately the housing market itself.
The glorification of homeownership as a path to wealth may even be one of the forces sustaining America’s NIMBY problem.
Renting and owning are different products
Owning a home can be a good choice. It gives people greater control over their living space, protection from a landlord deciding not to renew a lease, and a way to establish long-term roots in a community. A fixed-rate mortgage can also provide some predictability, and paying down the principal creates a form of forced saving.
Renting offers a different set of benefits. Renters can move more easily when their work, relationships, or preferences change. They do not have to assume the risk of a major structural repair, spend weekends maintaining a property, or pay the substantial transaction costs associated with buying and selling. Renting may also allow someone to live in a neighborhood where purchasing a comparable home would be prohibitively expensive.
Neither option is universally superior. They solve different problems and expose households to different risks.
Someone who wants control, permanence, and the ability to modify a property may reasonably prefer ownership. Someone who values mobility, convenience, and financial diversification may reasonably prefer renting. These are personal tradeoffs, not stages in a hierarchy in which the renter is always waiting to graduate into ownership.
Renting is not necessarily a financial mistake
The financial case for homeownership is also less straightforward than popular advice suggests.
Comparisons between renting and buying frequently compare rent with a mortgage payment. But these are not equivalent numbers. Part of a mortgage payment goes toward principal and therefore increases the owner’s equity. Other ownership expenses, however, produce no equity at all.
Mortgage interest, property taxes, insurance, maintenance, repairs, closing costs, selling costs, and the opportunity cost of the down payment are all real expenses. A homeowner who places $100,000 into a down payment also gives up whatever return that money could have earned in a diversified portfolio.
In his analysis of the decision to rent or buy, Ben Felix argues that the useful comparison is between rent and the unrecoverable costs of ownership, rather than between rent and the entire mortgage payment. His simplified “5% rule” accounts for property taxes, maintenance, and the opportunity cost of capital. The precise calculation depends on current interest rates, expected investment returns, taxes, maintenance expenses, and local housing prices, but the broader principle remains useful: mortgage payments are not the only cost of owning a home. (Ben Felix, “Rent or Own Your Home? A Handy 5% Rule”)
Ownership also creates concentration risk. A homeowner may have most of their net worth invested in one leveraged property, in one neighborhood, and in one metropolitan economy. A renter who invests the difference between renting and owning can instead hold a diversified portfolio containing thousands of companies across many countries.
Housing prices can rise dramatically, but appreciation is not guaranteed for every home, city, or period. Owners who need to move during a downturn may discover that their supposed source of stability has reduced their mobility. Transaction costs make short ownership periods particularly risky because the property must appreciate enough to overcome the expenses involved in buying and selling.
The decision also depends on behavior. Homeownership can function as forced saving because homeowners must make their mortgage payments each month. A renter only achieves the projected financial benefits of renting if they actually invest some of the money they save. The financial comparison therefore depends not only on market returns, but also on the habits of the people involved.
The Rational Reminder podcast’s detailed discussion of renting and buying reaches a similarly nuanced conclusion: the financially preferable option depends on prices, rents, expected returns, borrowing costs, taxes, maintenance, the length of ownership, and the household’s ability to save consistently. (Rational Reminder, Episode 154, “Renting vs. Buying a Home: How to Decide”)
None of this means renting is always financially better. Many homeowners have accumulated substantial wealth through appreciation, mortgage leverage, forced saving, and favorable tax treatment. Ownership can produce an excellent financial outcome.
The point is that the outcome depends on the purchase price, rent for a comparable property, mortgage rate, maintenance costs, taxes, investment returns, holding period, and future home-price appreciation. It cannot be reduced to “renting wastes money” and “buying builds wealth.”
Government should not confuse homeownership with housing success
Despite these tradeoffs, American housing policy heavily favors ownership.
The federal government supports homeowners through mortgage guarantees, preferential financing, the mortgage-interest deduction, favorable treatment of capital gains from home sales, and other tax provisions. These policies are often described as promoting housing stability and helping households build wealth.
The distribution of support, however, is far from neutral. According to the Urban Institute, the federal government provides more than three times as much through tax benefits that assist homeowners and investors, who are disproportionately middle- and high-income, as it spends on housing assistance for low-income renters. (Urban Institute, “How Does the Federal Government Support Housing?”)
These policies are frequently defended as ways to increase homeownership. But policies that subsidize demand can instead increase the amount buyers are able to bid for a limited supply of homes. When housing construction cannot respond, some of the subsidy may be captured through higher prices rather than improved affordability.
Research on Denmark’s mortgage-interest deduction illustrates this possibility. Economists Jonathan Gruber, Amalie Jensen, and Henrik Kleven found that changes to the deduction had essentially no effect on whether people became homeowners. Instead, the deduction affected how much housing existing owners purchased and how much debt they carried. The United States is not Denmark, but the finding demonstrates that a subsidy presented as encouraging homeownership can primarily influence the size and financing of purchases made by people who would have owned anyway. (Gruber, Jensen, and Kleven, “Do People Respond to the Mortgage Interest Deduction?”)
A higher homeownership rate is not, by itself, proof that people are better housed. A household pushed into an unaffordable mortgage is not necessarily better off than one with a secure and reasonably priced lease. A renter should not have to assume a large, leveraged position in local real estate to receive stability, dignity, or a meaningful opportunity to build wealth.
The goal of housing policy should be to give people access to safe, stable, and affordable homes. It should not be to move as many households as possible into one particular financial arrangement.
When a home becomes a retirement account, scarcity becomes desirable
The most damaging consequence of America’s homeownership obsession may be the political incentives it creates.
For many households, a home is not merely somewhere to live. It is their largest asset, their primary source of wealth, and a central part of their retirement plan. After being told for decades that buying a home is the way to build wealth, owners understandably become highly sensitive to anything that might threaten its value.
This creates a fundamental conflict.
Affordable housing requires homes to remain relatively inexpensive. Successful housing investment requires existing homes to become more expensive.
At the individual level, hoping that your home appreciates is perfectly rational. At the societal level, expecting millions of households to build wealth through ever-rising housing prices is incompatible with keeping housing affordable for the next generation.
Once homeowners become financially dependent on appreciation, restrictions on new housing can begin to look attractive. A proposed apartment building, duplex, or condominium development is no longer merely a change to the neighborhood. It can be perceived as competition for the owner’s most important asset or as a threat to the exclusivity that helps support its value.
This does not mean every homeowner opposes construction, that every development objection is financially motivated, or that homeownership is the sole cause of NIMBYism. People may oppose development because of concerns about infrastructure, design, displacement, environmental effects, traffic, schools, or public services. Some of those concerns may be legitimate.
But the financial structure of homeownership gives existing owners a reason to care about maintaining scarcity. When a household has been encouraged to treat its home as both shelter and an investment, policies that might reduce housing prices can appear personally threatening even when they would benefit the broader community.
The effects of restrictive housing policy are well documented. A major review of the economic literature by Joseph Gyourko and Raven Molloy concluded that regulation generally appears to raise housing prices, reduce construction, and make housing supply less responsive to demand. (Gyourko and Molloy, “Regulation and Housing Supply”)
The benefits of this scarcity flow disproportionately to people who already own property. The costs are imposed on renters, younger households, people moving for work, and prospective buyers who have not yet entered the market.
Existing residents also possess a structural advantage in local politics. They can attend hearings, organize neighborhood groups, contact elected officials, and object to individual projects. The people who would have lived in housing that is never built are not yet residents and therefore have little or no political representation in the process.
The result is a system in which current owners can protect the scarcity value of their assets by limiting opportunities for the people who come after them.
The homeownership feedback loop
This produces a destructive cycle:
Homeownership is promoted as the primary route to middle-class wealth.
Households place much of their savings into a single property.
Those households become dependent on rising property values.
They acquire a financial incentive to resist construction or policy changes that might reduce those values.
Restricted construction makes housing more expensive for renters and prospective buyers.
Because housing has become more expensive, the people who managed to buy appear increasingly wealthy compared with those who did not.
Policymakers then conclude that even more people must be helped into homeownership.
The widening wealth gap between owners and renters is interpreted as evidence that everyone should own. But part of that gap is produced by policies that subsidize owners, constrain supply, and allow existing property owners to capture the benefits of scarcity.
The system manufactures the advantage and then presents that advantage as proof of the system’s wisdom.
Policies that help owners can actively harm renters
It is tempting to treat policies that increase property values as harmless benefits for homeowners. But higher property values are not free money. They represent higher acquisition costs for future buyers and, over time, can contribute to higher rents.
A homeowner may celebrate when the value of their house rises by $100,000. For the household that hopes to buy that house, the same change is a $100,000 increase in cost.
Similarly, a neighborhood that blocks new apartments may protect the scarcity and value of existing homes, but it does so by preventing additional households from living there. Renters face fewer choices and more competition for the units that remain. Prospective buyers must bid against one another for an artificially limited supply.
Even policies intended to help first-time buyers can become counterproductive when they increase purchasing power without increasing construction. If every eligible buyer receives more money to compete for the same limited number of homes, sellers may capture much of the benefit through higher prices.
This is why maximizing the homeownership rate is not necessarily a renter-neutral policy. Depending on how it is pursued, it can strengthen the political constituency for scarcity, increase housing demand without increasing supply, and direct public resources toward people who are already comparatively advantaged.
A policy can help an individual household purchase a home while making the broader housing system less affordable.
A tenure-neutral housing policy
Rejecting the worship of homeownership does not require opposing homeownership. People who want to own should have that opportunity, and public policy should address genuine barriers such as discrimination, exclusionary zoning, limited access to credit, and insufficient housing construction.
But policy should be more neutral about whether a household rents or owns.
That would mean judging housing policy by affordability, security, quality, mobility, and access to opportunity rather than primarily by the homeownership rate.
It would mean giving renters greater stability through enforceable housing standards, predictable lease rules, appropriate protections against arbitrary displacement, and a sufficient supply of housing that landlords must compete for tenants.
It could also mean offering renters better opportunities to build wealth outside real estate. Homeowners benefit from tax-advantaged appreciation, leverage, and forced saving. Renters could be supported through broader access to retirement accounts, matched savings programs, renter tax credits, or other policies that do not require purchasing a leveraged and undiversified asset.
Most importantly, tenure-neutral policy would allow substantially more housing to be built, particularly in desirable neighborhoods with access to employment, public transportation, schools, and other opportunities. Research on zoning reforms suggests that permitting greater density can increase housing availability and reduce prices relative to places where restrictions remain unchanged. (Greenaway-McGrevy and Phillips, “Estimating the Economic Value of Zoning Reform”)
A tenure-neutral housing policy would also require acknowledging that indefinitely rising home prices are not an unqualified public good.
A home can be a good investment for its owner. But housing cannot simultaneously become more affordable if every existing home is expected to generate extraordinary investment returns.
The United States does not need to eliminate homeownership or discourage people from buying homes. It needs to stop treating renters as people who have failed to buy and stop treating housing scarcity as wealth creation.
A successful housing system is not one in which everyone owns.
It is one in which everyone has a good place to live.
If you look at how many U.S. suburbs are built today, a clear pattern emerges. There’s the wide arterial road, often called a stroad. It’s usually six to eight lanes, built for speed. Along both sides sit strip malls, big-box stores, and standalone restaurants, each surrounded by large parking lots.
Branching off these roads are residential subdivisions. These neighborhoods are made up of winding streets and cul-de-sacs. They’re quiet and low-traffic by design, but they’re also difficult to navigate without a car. There are few direct paths, and no real reason to pass through unless you live there.
This layout reflects a simple assumption: everyone drives everywhere. But that assumption starts to break down once autonomous vehicles enter the picture.
The reason commercial areas have such large parking lots is straightforward. People drive from home, park, do what they need to do, then drive back. Every destination needs enough space to store all those cars at peak times.
Autonomous vehicles, especially shared robo-taxis, change that. Instead of parking, a car can drop you off and immediately leave to pick up someone else. The same vehicle can serve many people throughout the day. That makes parking far less necessary.
Once you don’t need acres of parking, that land becomes available for something else. A small pick-up and drop-off area can handle the same flow of people while taking up a fraction of the space.
The rest can be redeveloped. More shops, housing, parks, or public space. Instead of walking across a hot, empty parking lot, you step into a place designed for people. Buildings can line the street, provide shade, and create a more comfortable environment.
This also changes how transit works along these roads. Right now, buses often run infrequently and stop in places that feel hostile. You get off and face a long walk across a parking lot. There’s little shelter, a lot of noise, and constant traffic.
If those parking lots are replaced with actual development, the experience improves immediately. You step off the bus and you’re already close to where you want to go. There are buildings, shade, and activity right there. More people live and work along the corridor, which makes transit more useful. Higher ridership can support more frequent service and eventually better infrastructure like dedicated lanes or light rail.
These wide arterial roads already have the space for that shift. Some lanes can be repurposed for transit, wider sidewalks, or protected bike lanes without removing cars entirely.
Inside the subdivisions, a similar change becomes possible. Today, it’s hard to introduce small businesses into single-family neighborhoods, largely because of parking requirements. A small coffee shop, for example, would need enough parking for customers and staff, which often isn’t feasible.
If people arrive by autonomous vehicle, bike, or on foot, that requirement shrinks or disappears. A house could be converted into a small café, a barber shop, or a studio without needing a large parking area. These kinds of businesses could serve the immediate neighborhood instead of drawing large crowds from far away.
The street layout inside these neighborhoods can improve too. Cul-de-sacs are effective at limiting car traffic, which many residents like, but they also make walking inefficient. Two nearby points can require a long, indirect route.
You don’t have to redesign everything to fix that. Keeping the cul-de-sacs for cars while adding pedestrian and bike paths between them can create direct connections. What used to be a long walk becomes a short one. That makes it practical to walk or bike to nearby destinations within the neighborhood.
Taken together, these changes point to a different version of suburbia. Parking lots are replaced with housing, shops, and public space. Arterial roads become more balanced, supporting transit, walking, and biking alongside cars. Neighborhoods gain small-scale businesses. Walking and biking become more realistic options because distances shrink and routes improve.
People can still live in single-family homes. They can still use cars when they need to. But they’re no longer locked into one way of moving through the world, and the places they go feel better when they get there.
Autonomous vehicles don’t fix everything, but they remove one of the biggest constraints shaping suburban design: the need to store cars everywhere. Once that constraint is gone, a lot of new possibilities open up.
I’ve been thinking a lot about prediction markets lately. And honestly, I keep running into people who really don’t like them. Not just mild skepticism, more like “these should be banned” or even outright illegal. That reaction kind of bums me out.
I’ve been into the idea for a long time, even before there were any big platforms. Back when it was mostly just theoretical, before Polymarket, Kalshi, all that, I thought it was a really elegant concept. It just made sense. We already know markets can be pretty good at aggregating information. The stock market, for example, does a decent job pricing in everything people know (or think they know), and that usually leads to pretty accurate valuations. Way better than small private markets where fewer people are involved and less information gets reflected.
So if you start from the basic problem, “we want to predict the future,” it feels natural to look for systems that are good at combining lots of information. Prediction markets fit that really well. They’re kind of like a general-purpose forecasting tool. You can point them at almost anything.
One example I really like is weather markets. Kalshi has some live ones where you can predict things like temperature or whether it’ll rain on a specific day. That’s a case where prediction markets actually feel useful in a very direct way. Everyone cares about the weather. You’re planning a weekend, a trip, even just tomorrow, having a solid sense of what’s coming matters.
Sure, you can check a weather app or watch the forecast. And they’re usually fine. But the people trading in a weather prediction market are pulling from all of that too, plus their own models, their own insights, maybe even niche data sources. They’re constantly updating their beliefs because there’s money on the line. And that pressure forces information into the price.
Over time, the people who are actually good at predicting, like really good, end up with more influence because they win more and can trade more. So the market kind of self-selects for accuracy. The end result is a price that reflects a very informed, constantly updated probability. In theory, it’s about as good an estimate as you can get.
That’s kind of amazing, if you think about it. A single number that summarizes everything people collectively know (and believe) about some future event. It feels like a genuinely powerful tool. Which is why it’s frustrating to see people want to shut it down entirely, it feels like throwing away something valuable.
Now, to be fair, there are criticisms.
One that comes up a lot is insider trading. People don’t like the idea that someone with privileged information could profit off it. And yeah, I get why that feels unfair, especially since we regulate that heavily in stock markets.
But prediction markets aren’t really about fairness in that sense. They’re not trying to give everyone an equal shot. If that’s the goal, there are plenty of games for that, go play roulette or something. The whole point here is accuracy.
From that perspective, insider trading isn’t a flaw, it’s kind of the point. If someone knows something the market doesn’t yet reflect, you want them to trade on it. That’s how the information gets incorporated into the price. It actually makes the market better as a forecasting tool.
Another criticism is that this is basically just gambling with extra steps. Especially with things like sports or politics. And yeah, I think there’s something to that. Gambling can be a real problem for some people, and a lot of these markets, especially sports, do look a lot like betting.
Honestly, I don’t think sports prediction markets add much value. Predicting who wins a game doesn’t really matter in any meaningful sense. It’s entertainment. So if people want to clamp down there, I’m not too bothered by that.
Politics is a bit more nuanced. There’s arguably some real value in forecasting elections. Markets can sometimes pick up on signals that polls miss. But even then, I could see the case for tighter rules or guardrails.
Where I think we’d really lose something is in the more practical, information-heavy markets, like weather, economic indicators, maybe even things like supply chain risks or disease outbreaks. Those feel genuinely useful. They help people make decisions.
So yeah, I don’t think prediction markets are perfect. But as a tool for aggregating information and forecasting the future, they’re kind of incredible. It would be a shame to throw that away entirely.
I’ve never liked strip malls, but for a long time I couldn’t quite explain why. The buildings themselves aren’t especially offensive. If you strip away the context, a strip mall is not so different from a row of shops that you might find present on a quaint walkable Main Street in a small town.
The problem is that unlike a main street, the strip mall is sitting behind an enormous moat of parking that makes it very difficult to get to for anyone not in a car. In order to reach the shops from the street you must cross a wide, hot, unshaded expanse of asphalt which is quite unpleasant.
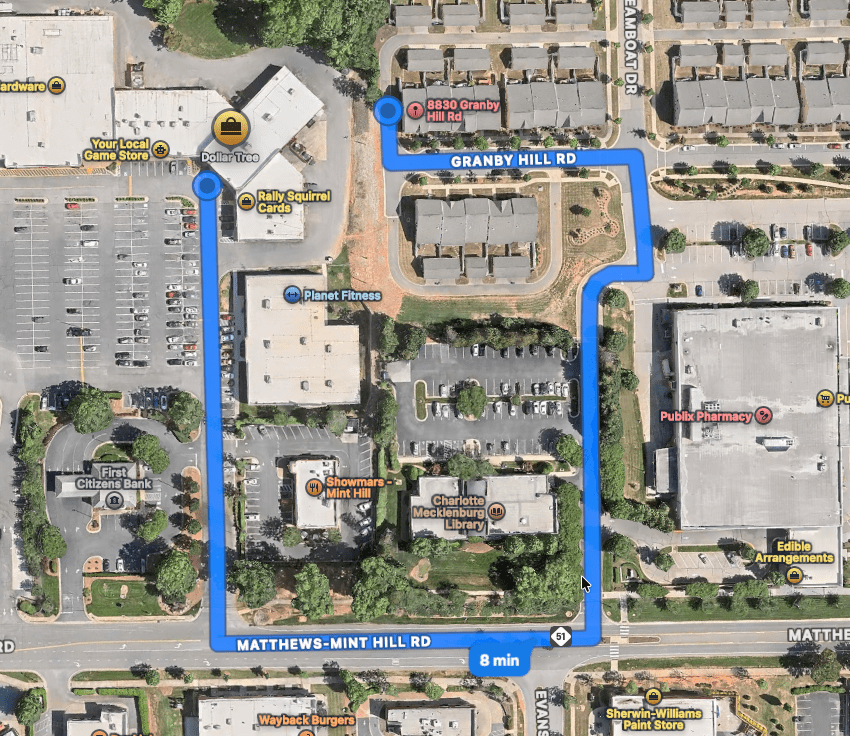
They’re also usually separated from housing. Even when homes are physically close, they’re rarely connected in a way that makes walking easy. For example, take a look at this typical American strip mall located in Mint Hill, NC with a residential development less than 50 feet away. However, because there is no pedestrian connection between the two places the official walking route is nearly half a mile and requires walking along a busy road.
So almost everyone arrives the same way: by car, which then sits in that giant parking lot until they leave.
The assumption that every visitor must store a private vehicle on site for the duration of their visit is what drives the need for dedicating so much land to car parking.
But that assumption may begin to change over the coming decade.
We are seeing rapid improvements in autonomous vehicles from companies like Waymo, such that I think there is a good chance private vehicle ownership may give way to robotaxis if they can be made cheaper per mile.
If people increasingly rely on on-demand transportation, especially autonomous vehicles, destinations won’t need to dedicate vast areas to parking. A vehicle could drop someone off and leave. The site would only need enough space to stage a limited number of robotaxis so that departures are reasonably quick. That’s very different from storing approximately one vehicle per person in the building.
And once you stop designing around having space to store one car for every person, a lot of land becomes available for other more productive uses.
I would suggest that we should build infill housing on disused shopping center parking lots.
If most of the parking lot were replaced with townhomes, and perhaps a small apartment building, the character of the place would change immediately for the better. The bland soulless strip malls of modern day suburbia would be transformed into the cozy pleasant Main Streets of the past and become a place people actually want to spend time.
Take the strip mall that I mentioned earlier from Mint Hill, it has a general store, a small hardware store, a pizza place, a nail salon, a hair cutter, a gym, and a specialty shop or two. These are everyday businesses that are actually useful to live near. Being able to walk to get a haircut or pick up a few household items would be convenient.
Yet the layout makes living near them awkward or impossible.
Instead of a field of parked cars, imagine a shaded street lined with homes. Doors and windows facing the shops. A small green space tucked between buildings. Paths connecting to adjacent neighborhoods that currently sit cut off by massive six lane stroads (wide, high-speed arterial roads).
A short, direct link to the existing nearby townhome neighborhood would make the shops part of the neighborhood instead of a separate island. Residents could walk over in a few minutes instead of driving around to the main entrance.
People coming from farther away could still arrive by car, autonomous or otherwise, or by transit.
This kind of infill would make bus service along arterial roads more practical. Strip malls are usually located on major corridors. If housing filled in the parking lots along those corridors, there would be more people within walking distance of each transit stop and more destinations clustered together. For transit riders, the modern-day torturous walk across an expanse of hot asphalt with the sun beaming down on you, would be replaced with a pleasant stroll through tree lined neighborhood streets with shaded sidewalks.
By adding this infill housing we can also help alleviate the issues that many cities in the U.S. are experiencing with regard to a housing shortage in the parts of the city where people want to live. Many regions are short on homes, yet large portions of urbanized land are devoted to parking that sits partially empty much of the time. Reusing that space for housing adds units without expanding outward. It places residents close to daily needs. Some vehicle trips disappear entirely because they can be done on foot.
The underlying strip mall structure isn’t inherently flawed. It’s adaptable. What makes it unpleasant is the dominance of parking and the lack of integration with surrounding neighborhoods.
If the parking requirement shrinks, whether because of changing transportation patterns or different policy choices, the opportunity is straightforward. Build homes where the asphalt is. Connect surrounding neighborhoods to the shops. Let the existing storefronts function as a local town center rather than a drive-to outpost.
The difference between a hostile shopping center and a livable neighborhood might be less about architecture and more about what we decide to store on the land in front of it.
When you drive on a busy road, you always pay a price. The real question is how you pay it, with money or with time.
In most of the United States, we have chosen to charge drivers in time. There is no toll for entering a congested road, but during peak hours you might spend an hour commuting when the same trip would take 20 minutes with no traffic. Because there is no monetary cost, the time price people are willing to tolerate rises dramatically, and congestion becomes the norm.
The problem with using time as the cost is that it creates bad incentives, especially around carpooling.
Imagine two people traveling from the same neighborhood to the same restaurant across town. They could drive separately or share a car. If traffic makes the trip take an hour either way, there is no time savings from sharing. Each person still loses an hour. Given that, many people will choose separate cars so they can control their own music, podcasts, or comfort. Time-based pricing gives no reward for reducing the number of vehicles on the road.
Now consider the same trip with congestion pricing. Suppose there is a $10 toll, and as a result traffic flows freely and the trip takes 20 minutes. If the two people drive separately, they pay $20 total. If they share one car, they pay $10 total, or just $5 per person. Suddenly, carpooling has a clear, direct benefit.
That incentive scales. Larger groups are pushed toward higher-capacity vehicles like buses and trains, where the toll cost per person becomes almost negligible. A $10 toll split among 20 bus riders is just 50 cents each. At that point, the toll barely matters, especially if it is offset by fares.
Once pooling becomes economically attractive, this also opens the door to entirely new transportation options. Private bus services, pooled taxi services, and on-demand shuttles become much more viable in a congestion-priced world. When the road cost is shared across many riders and travel times are predictable, these services can compete effectively with private cars while offering convenience and flexibility that traditional public transit may not always provide.
This shift matters because traffic engineers should not be optimizing for the number of cars moved on a road. They should be optimizing for the number of people. Congestion pricing encourages fewer vehicles to carry more people, which reduces traffic and moves everyone faster.
There are secondary benefits too. Revenue from congestion pricing can fund better public transportation, improving affordability and access. Wealthier drivers can still choose to pay higher tolls to use private cars during rush hour, as long as traffic keeps flowing and high-capacity vehicles are not stuck.
In fact, if congestion pricing truly eliminates traffic, some dedicated bus lanes may become less necessary. Their primary purpose is to help buses avoid congestion. If congestion disappears for everyone, the system becomes simpler and more flexible, even on roads where bus lanes are not feasible.
In short, you pay the cost of driving either way. Making that cost monetary instead of temporal creates far better incentives, rewards efficient behavior, and allows cities to move more people in less time.
I’ve always found treadmill walking to be exceptionally boring. If I’m outside, on a park trail, a greenway, or any kind of walking path, I can walk for hours without thinking about it. The time just disappears. Put me on a treadmill indoors, staring forward at the same wall or the same row of machines, and suddenly even twenty minutes feels long.
Right now, though, walking outside isn’t really an option. The weather is cold, the wind is unpleasant, and I am not motivated enough to bundle up just to be uncomfortable the entire time. So I’m stuck indoors with the treadmill, trying to find something that makes it feel less monotonous. That was the mindset I was in when I decided to try using my Xreal display glasses while walking.
The idea was simple. If treadmill walking is boring because there is nothing to look at and no sense of movement through space, maybe I could fake that feeling. Not perfectly replicate walking outdoors, but at least add some variety and visual interest so it does not feel like I am just walking in place.
I found that there is a whole category of YouTube videos that are just someone walking while filming. No narration, no edits, just long, continuous footage of moving through an environment. These videos are usually around an hour long, so during my walk I managed to get through two of them.
The first was a nature walk along a waterfront, with mountains, waterfalls, and a bit of light hiking. The second was a fully CGI walk set in the Harry Potter universe, starting at the train station and ending at Hogwarts. That one could have easily felt cheesy, but it was actually surprisingly engaging while walking.
What caught me off guard was how well the illusion worked. Making the virtual screen as large as possible turned out to be important. Even though the screen did not fit entirely in my field of view, I could move my head slightly to look at different parts of the scene, which made it feel less like watching a video and more like being present in the space.
Audio, unfortunately, was where things fell apart a bit. Normally when I walk, I am listening to music or a podcast. With this setup, at least on iOS, that was not really possible. As far as I can tell, the system only allows one audio source at a time, so if you are playing a YouTube video, you cannot also play music in the background.
I assumed I could just mute the video, but the YouTube app does not actually have a mute option. The only way to silence it is to turn the system volume all the way down, which also kills your music. I tried watching in the browser so I could mute the tab, but then I could not full-screen the video. So I had to choose between full screen with audio I did not want, or muted audio with a worse visual experience.
It is frustrating, because the ideal setup would be to mute the walking video entirely and listen to a podcast while visually moving through these environments. Maybe Android handles this better. I honestly do not know. And maybe this kind of thing improves if Apple ever releases their own display glasses with tighter OS-level integration. For now, it is a real limitation.
Even so, the walk was still more enjoyable than a normal treadmill session. Instead of music, I ended up listening to the ambient sounds from the videos. Footsteps, gravel, water, and background noise. It was not what I planned, but it turned out to be oddly calming, and the time passed much faster than usual.
After I finished the walking videos, I tried watching an episode of Friends while still walking. That worked well too, but in a different way. For the walking videos, I wanted the screen to feel huge and immersive. For a TV show, a smaller screen was clearly better. Being able to see the entire frame at once matters more for traditionally shot content.
I also experimented with display modes. For treadmill walking, anchor mode was clearly the right choice. With anchor mode, the video stays fixed in space, so you can look around within it. That made the walking videos feel much more natural, especially since my own movement lined up reasonably well with what I was seeing.
Follow mode just felt off. Since the screen moves with your head, it is hard to focus on any one part of the image. As soon as you try to look at something off to the side, the whole display shifts. For this kind of use, anchor mode is not just better. It is basically required.
Comfort and safety were things I paid close attention to. I did not feel motion sick at all, and I never felt unsteady. That is a big reason I would not try this with a fully immersive VR headset like a Quest 3 or Vision Pro. With the Xreal glasses, you still have a clear view of the real world, especially in your peripheral vision. You are never completely cut off from your surroundings, which makes walking on a treadmill feel much safer.
There was one visual issue worth mentioning. During one of the walking videos, the scene moved indoors and became fairly dark. I was in a brightly lit gym, and in that situation I started noticing reflections in the display. Specifically, I could see reflections of my legs and feet moving below me. I think that is due to the angled nature of the display reflecting whatever is directly underneath it. As soon as the video returned to a brighter outdoor scene, the problem disappeared. Still, it is something to be aware of if you are watching dark content in a bright room.
Overall, I would do this again without hesitation. I went into it just trying to make treadmill walking less miserable, and I ended up with something that genuinely made the experience more engaging. It did not replace walking outdoors, but it did a decent job of capturing some of that feeling. Movement, variety, and the sense that you are actually going somewhere instead of just counting down the minutes.
I recently picked up a pair of Xreal 1S display glasses with one very specific goal in mind: something I could use on longer trips on planes, trains, and buses to watch movies and TV without hauling around a full VR headset or squinting at my phone.
This is my first pair of display glasses, but I’ve spent time at both ends of the spectrum. I’ve owned full VR headsets like the Quest 2, Quest 3, and the Apple Vision Pro. Those give you a giant virtual screen, but they’re heavy, bulky, and not something you casually bring on a trip.
At the other extreme are products like the Meta Ray-Bans. They’re basically normal glasses with a bit of tech sprinkled in. Convenient, yes. Useful for watching a movie on a plane, not really.
The Xreal glasses sit in the narrow space between those two worlds. They don’t try to be a full immersive VR system, and they’re not just smart glasses with a few novelty features. They’re aimed squarely at one thing: acting like a portable, private screen you can actually use while you’re in transit.
Apple markets the Vision Pro heavily as a movie-watching device, but I never enjoyed that experience. The headset is heavy, and I never stopped being aware that it was strapped to my face. That’s very different from normal glasses, where after a few minutes you mostly forget they’re there. On top of that, the Vision Pro is fragile, bulky, and impractical to travel with. Bringing it along just to watch something on a plane or train would take up most of my personal item space, and it never felt worth it.
The Quest 3 has similar issues. It’s lighter and cheaper, so I worried less about damaging it, but it’s still awkward to travel with and not something I’d casually toss into a bag.
That’s where I hoped the Xreal glasses would be different, and for the most part, they are. They’re small and light enough to fit easily into a backpack, or even a fanny pack if you really wanted to. That alone makes them far more realistic to bring on public transportation. They’re also light enough that they don’t feel like they’re dragging your face down after half an hour.
Another thing I like is that they don’t have an onboard computer. Everything comes from my iPhone. That means one less device to charge or think about when I’m traveling. The glasses do drain my phone battery faster, but I already carry battery packs anyway. I have a MagSafe battery that snaps onto the back of my phone and charges it wirelessly, and I can still plug the glasses into the USB port at the same time. That setup works well enough that I didn’t need to buy anything extra.
I do wish there were a wireless option. Having a cable plugged into the phone adds friction, especially when you’re shifting around in a seat. Being able to just AirPlay to the glasses would be ideal. I understand why it’s wired, since the phone is also powering the glasses, but it’s still something I notice.
Because the glasses simply mirror my phone, every iOS app works. This turned out to be a bigger deal than I expected. On VR headsets, app support is always spotty. The Vision Pro still lacks official apps for major services like YouTube and Netflix, and on the Quest you often end up watching content through a browser. That’s fine at home, but it’s frustrating when you’re on a plane or train and want offline downloads to actually work.
With the Xreal glasses, I just download content ahead of time using the native apps. Netflix, YouTube, whatever. It all works exactly the way it does on my phone, with no workarounds.
One thing I really don’t like is that the iPhone screen has to stay on for the glasses to keep displaying content. Ideally, the phone would behave like it’s connected to an external monitor and let me turn the screen off. That would save battery and feel much cleaner. Because the screen has to stay on, I had to disable auto-lock while using the glasses. I hate doing that. Auto-lock is a basic security feature, and I’ve already had a few moments where I set my phone down, forgot about it, and came back later to find the screen still on.
For now, I’m manually toggling auto-lock on and off when I use the glasses. It works, but it’s annoying, and it feels like something Apple should be able to improve eventually.
The displays themselves are better than I expected. I’ve tried doing real work in VR before, and it never stuck. With the Vision Pro, the resolution was incredible and text looked perfect, but the headset was too heavy to wear comfortably for long stretches. With the Quest 3, I didn’t even get that far because the resolution wasn’t good enough for reading code. Text felt blurry and pixelated, and I gave up quickly.
Out of curiosity, I tried working in the Xreal glasses on my laptop while sitting on the couch. I managed about two hours without much trouble and probably could have gone longer. The text isn’t as sharp as the Vision Pro, but it’s noticeably better than the Quest 3. Clear enough that I didn’t feel eye strain or frustration.
That said, I’m not replacing my monitors. I still prefer a normal setup, and wearing what look like oversized sunglasses during a Zoom call would look ridiculous. But as an occasional option, it worked better than I expected.
Where the glasses really shine is watching movies and TV. You don’t need extreme resolution for that, and I actually prefer keeping the virtual screen a bit smaller so nothing clips at the edges of the field of view. The field of view isn’t huge, but it’s large enough that it doesn’t bother me.
The glasses have two display modes. One anchors the screen in space, and the other has it follow your head. For movies, I prefer the follow mode. For work, the anchored mode makes more sense, since you can look toward different parts of the screen without the whole thing shifting around.
They also include a feature that converts content into 3D. I was excited to try it, but was underwhelmed. It’s fine, but not great. It tries to guess what should pop out of the screen, and the results are inconsistent. Sometimes it’s more distracting than immersive. I turned it off after a few minutes and haven’t really felt the urge to use it again.
These are more comfortable than a VR headset, but they’re still not normal glasses. After a while, the nose pads start to bother me, and the top of the glasses gets warm. Not hot, just warm enough that you notice it. Little things like that add up and remind you that you’re wearing something on your face.
I don’t think I’ll use these much at home. I originally thought they might be nice for lying on the couch when the TV angle is bad, but I don’t find them comfortable enough to choose over just holding a tablet or phone.
Overall, for what I bought them for, watching movies and TV while traveling, I’m very happy with the Xreal 1S glasses. They hit a sweet spot that VR headsets miss by being small, light, and practical. I don’t expect to use them for much beyond travel, but for that specific niche, they work surprisingly well.
One other use case I’m curious about, but haven’t tried yet, is wearing them on a treadmill or exercise bike to watch content more comfortably. That might be a future experiment. For now, they’ve earned a spot in my travel bag.
Bilt dropped details yesterday about their new credit cards. I’ve been using the original Bilt card for a little over a year, mostly for one very specific reason, and after reading through the announcement I’m pretty confident I won’t be switching to any of the new ones.
I’ll probably just close the account at the end of the month and go back to paying rent directly out of my bank account.
The original Bilt card worked because it did one thing unusually well. It let you pay rent with no fee and earn points on it. You got an account number and routing number, gave that to your landlord, and rent came out like it was a checking account. One point per dollar on rent. Simple.
My rent is about $2,000 a month, so that came out to roughly 2,000 points every month. That’s not a ton of money, maybe $20 in value, but it was enough to matter in small ways. I mostly used the points for Lyft rides. Not flights, not aspirational travel redemptions, just “cool, this ride is free.” A couple of those a month was nice. It felt like getting something back for an expense that otherwise just disappears.
There was a catch, though. You had to make at least five non-rent transactions per month to earn the rent points. And I never wanted to actually use the Bilt card for real spending. It wasn’t competitive with my other cards, and I didn’t feel like thinking about it.
So I did what a lot of people probably did. I gamed it. I put five recurring charges on the card: iCloud storage for 99 cents, a few other subscriptions in the $5 to $10 range, and called it a day. Total monthly spend outside of rent was maybe $30. Rent was thousands. Points flowed.
From Bilt’s perspective, I was almost certainly a terrible customer.
Which is why none of this is surprising.
The new cards are clearly designed to stop people from using the product the way I was using it. Under the new setup, if you want to earn points on rent, you need to spend a lot more elsewhere on the card. Roughly 75% of your rent amount, from what I can tell. If your rent is $2,000, you need to put about $1,500 of other spending on the card every month.
That’s where it completely falls apart for me.
I’m not interested in rerouting $1,500 a month away from cards I already like just to preserve a rent reward setup that used to be effortless. Five token transactions was annoying but manageable. Rebuilding my entire spending strategy around one card is not.
And honestly, that’s fine. This feels very intentional. Bilt doesn’t want people who do the bare minimum, harvest rent points, and disappear. I was exactly that person. I don’t blame them for tightening things up.
But it does mean I’m done.
The new cards might be great for people who want a primary spending card and like the Bilt ecosystem. I’m not that person. I just wanted the rent thing to keep quietly working in the background, and it no longer does.
So I’ll take the small loss and go back to paying rent the old-fashioned way. No points, no Lyft credits, no Wells Fargo relationship I didn’t really want in the first place. It was fun while it lasted.
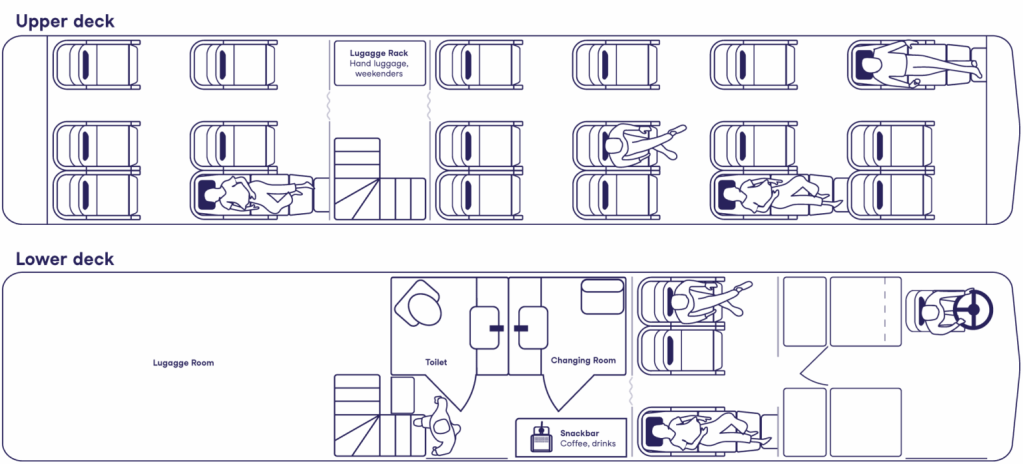
I recently came across an intercity bus service starting up in Europe that I haven’t been able to stop thinking about. It’s an overnight bus, but not in the usual sense. Instead of upright seats and cramped legroom, the buses are built around fully lie-flat seats, similar to what you’d find in first class on a long-haul flight.
Floor plan of a European luxury sleeper bus
The idea is almost obvious once you hear it. Airlines already know how to make seats people can actually sleep in for eight or ten hours. So what happens if you take that same idea and put it on a bus, where the trip is slower but much cheaper to operate? At that point the comparison is no longer bus versus plane, but time versus comfort.
If the entire trip happens while you’re asleep, the extra travel time matters a lot less. You board at night, go to sleep, and wake up somewhere else. There’s no early alarm, no airport security, and no sitting upright trying to doze for ninety uncomfortable minutes. In the best case, it barely feels like travel at all.
Where this really starts to make sense is for trips that are just a bit too long to drive comfortably in one day. I live in Charlotte, North Carolina, and some of my family lives in Orlando. That drive is about eight hours on a good day. It’s long enough that you lose a full day to it, but short enough that flying can feel like overkill once you factor in the airport time.
An overnight bus fits almost perfectly there. You leave Charlotte around 10 p.m., sleep through the night, and arrive in Orlando early the next morning. You didn’t spend the day driving, and you didn’t spend the night in a hotel. You just… arrived.
That said, there’s one part of the European implementation that I think really works against the whole idea. Many of these routes include multiple intermediate stops. A single bus might start in one city, stop in several others along the way, and keep going past your destination.
That sounds efficient on paper, but it creates a real problem for passengers. If you’re getting off at one of those intermediate cities, you may be forced to wake up at two or three in the morning. At that point the magic is gone. You’re tired, it’s dark, and there’s nowhere to go. Now you need a hotel anyway, which defeats one of the biggest advantages of the service.
I think these routes should be strictly point to point. One bus per corridor. Charlotte to Orlando. Charlotte to Tampa. Charlotte to Miami. Airlines fill planes on these routes every single day. There’s no reason a well-designed overnight bus couldn’t fill up too.
Going point to point also opens up something I think is crucial: treating the bus more like a hotel than a vehicle. Imagine arriving at your destination at 6 a.m. but not being forced off the bus immediately. Instead, your ticket includes a checkout time, maybe 9 or 10 a.m. If you want to get up and leave right away, you can. If you want to keep sleeping, you can do that too.
That small change makes a huge difference. It turns the experience into transportation plus lodging, rather than just a long ride.
Once you think about it that way, other details fall into place. Clean bathrooms are non-negotiable. Food should be available, even if it’s simple. A small breakfast option at the arrival depot would make mornings feel less rushed. Luggage handling could work the same way hotels do, with a claim system so people can leave when they’re ready instead of all at once.
In theory, you could even plan trips where you string together several of these overnight routes and barely use hotels at all.
This kind of service feels especially relevant in the United States. We used to have a far more extensive passenger rail network, but much of it is gone now, and recreating it at a national scale would take decades. What we do have is a massive interstate highway network that already connects most major cities.
Intercity buses can take advantage of that immediately. The infrastructure is already there, and it’s effectively subsidized. For trips in the seven-to-ten-hour range, a comfortable overnight bus could easily compete with flying for a lot of people.
Looking further ahead, this gets even more interesting when you consider autonomous driving. Long highway stretches are exactly where autonomy performs best. If the bus doesn’t need a human driver, that role could shift toward an onboard attendant instead. Someone whose job is to help passengers, keep things running smoothly, and generally make the experience better.
That kind of staffing change could actually improve the service rather than cheapen it.
This isn’t going to replace planes, and it’s not meant to. Nobody is taking an overnight bus from the East Coast to the West Coast. But for the many city pairs that sit in that awkward middle distance, this feels like a genuinely underexplored option.
I would be surprised if something like this doesn’t eventually appear in the U.S. Once someone gets the execution right, it’s the kind of idea that feels obvious in hindsight.