I was recently wondering which of the popular web search engines provided the best results and decided to try to design an objective benchmark for evaluating them. My hypothesis was that Google would score the best followed by StartPage (Google aggregator) and then Bing and it’s aggregators.
Usually when evaluating search engine performance there are two methods I’ve seen used:
- Have humans search for things and rate the results
- Create a dataset of mappings between queries and “ideal” result URLs
The problem with having humans rate search results is that it is expensive and hard to replicate results. Creating a dataset of “correct” webpages to return for each query solves the repeatability of the experiment problem but is also expensive upfront and depends on the human creating the dataset’s subjective biases.
Instead of using either of those methods I decided to evaluate the search engines on the specific task of answering factual questions from humans asked in natural language. Each engine is scored by how many of its top 10 results contain the correct answer.
Although this approach is not very effective at evaluating the quality of a single query, I believe in aggregate over thousands of queries it should provide a reasonable estimation of how well each engine can answer the users questions.
To source the factoid questions, I use the Stanford Question Answering Dataset (SQuAD) which is a popular natural language dataset containing 100k factual questions and answers from Wikipedia collected by Mechanical Turk workers.
Here are some sample questions from the dataset:
Q: How did the black death make it to the Mediterranean and Europe?
A: merchant ships
Q: What is the largest city of Poland?
A: Warsaw
Q: In 1755 what fort did British capture?
A: Fort Beauséjour
Some of the questions in the dataset are also rather ambiguous such as the one below:
Q: What order did British make of French?
A: expulsion of the Acadian
This is because the dataset is designed to train question answering models that have access to the context that contains the answer. In the case of SQaUD each Q/A pair comes with the paragraph from Wikipedia that contains the answer.
However, I don’t believe this is a huge problem since most likely all search engines will perform poorly on those types of questions and no individual one will be put at a disadvantage.
Collecting data
To get the results from each search engine, I wrote a Python script that connects to Firefox via Selenium and performs searches just like regular users via the browser.
The first 10 results are extracted using CSS rules specific to each search engine and then those links are downloaded using the requests library. To check if a particular result is a “match” or not we simply perform an exact match search of the page source code for the correct answer (both normalized to lowercase).
Again this is not a perfect way of determining whether any single page really answers a query, but in aggregate it should provide a good estimate.
Some search engines are harder to scrape due to rate limiting. The most aggressive rate limiters were: Qwant, Yandex, and Gigablast. They often blocked me after just two queries (on a new IP) and thus there are fewer results available for those engines. Also, Cliqz, Lycos, Yahoo!, and YaCy were all added mid experiment, so they have fewer results too.
I scraped results for about 2 weeks and collected about 3k queries for most engines. Below is a graph of the number of queries that were scraped from each search engine.

Crunching the numbers
Now that the data is collected there are lots of ways to analyze it. For each query we have the number of matching documents, and for the latter half of queries also the list of result links saved.
The first thing I decided to do was see which search engine had the highest average number of matching documents.
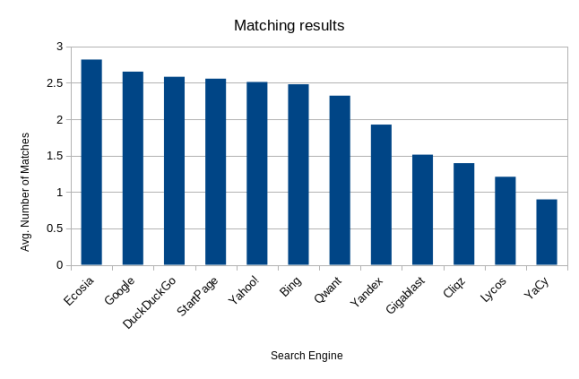
Much to my surprise, Google actually came in second to Ecosia. I was rather shocked with this since Ecosia’s gimmick is that they plant trees with the money from ads, not having Google beating search results.
Also surprising is the number of Bing aggregators (Ecosia, DuckDuckGo, Yahoo!) that all came in ahead of Bing itself. One reason may be that those engines each apply their own ranking on top of the results returned by Bing and some claim to also search other sources.
Below is a chart with the exact scores of each search engine.
| Search Engine | Score | Count |
| Ecosia | 2.82087177855552 | 3143 |
| 2.65397815912636 | 3205 | |
| DuckDuckGo | 2.58377701221422 | 3193 |
| StartPage | 2.55723270440252 | 3180 |
| Yahoo! | 2.51220442410374 | 2622 |
| Bing | 2.4809375 | 3200 |
| Qwant | 2.32365747460087 | 689 |
| Yandex | 1.92651933701657 | 1810 |
| Gigablast | 1.51381215469613 | 905 |
| Cliqz | 1.39724137931034 | 2900 |
| Lycos | 1.20962678758284 | 2867 |
| YaCy | 0.898050365556458 | 2462 |
To further understand why the Bing aggregators performed so well, I wanted to check how much of their own ranking was being used. I computed the average Levenshtein distance between each two search engines, which is the minimum number of single result edits (insertions, deletions or substitutions) required to change one results page into the other.

Of the three, Ecosia was the most different from pure Bing with an average edit distance of 8. DuckDuckGo was the second most different with edit distance of 7, followed by Yahoo! with a distance of 5.
Interestingly the edit distances of Ecosia, DuckDuckGo, and Yahoo! seem to correlate well with their overall rankings where Ecosia came in 1st, DuckDuckGo 3rd, and Yahoo! 5th. This would indicate that whatever modifications these engines have made to the default Bing ranking do indeed improve search result quality.
Closing thoughts
This was a pretty fun little experiment to do, and I am happy to see some different results from what I expected. I am making all the collected data and scripts available for anyone who wants to do their own analysis.
This study does not account for features besides search result quality such as instant answers, bangs, privacy, etc. and thus it doesn’t really show which search engine is “best” just which one provides the best results for factoid questions.
I plan to continue using DuckDuckGo as my primary search engine despite it coming in 3rd place. The results of the top 6 search engines are all pretty close, so I would expect the experience across them to be similar.
